Authors: Waldemar W. Koczkodaj, Dominik Strzalka, Jean-Pierr Magnot, Jiri Mazurek, James Peters, Michael Soltys, Jacek Szybowski, Arturo Tozzi, Hojjat Rakhshani
Title: On normalization of inconsistency indicators in pairwise comparisons
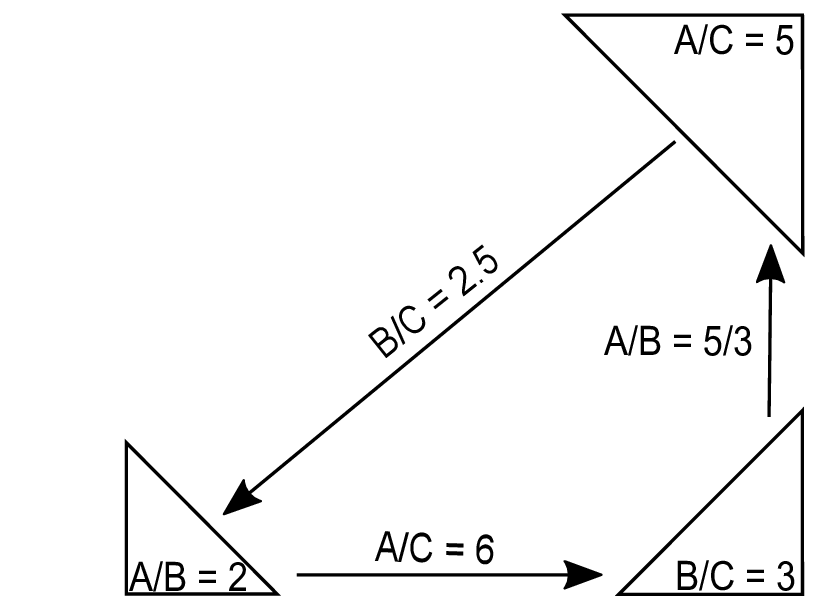 Abstract: In this study, we provide mathematical and practice-driven justification for using [0, 1] normalization of inconsistency indicators in pairwise comparisons. The need for normalization, as well as problems with the lack of normalization, are presented. A new type of paradox of infinity is described.
Abstract: In this study, we provide mathematical and practice-driven justification for using [0, 1] normalization of inconsistency indicators in pairwise comparisons. The need for normalization, as well as problems with the lack of normalization, are presented. A new type of paradox of infinity is described.
Accepted for publication in the International Journal of Approximate Reasoning, April 2017.