Blog
Presentation for AWS MLU
Machine Learning: Bridge from Education to Career, a talk at AWS Machine Learning University, March 3, 2022. The slides can be accessed here.
The best engineering interview question I’ve ever gotten, Part 1 – Arthur O’Dwyer – Stuff mostly about C++
It’s been a while since I was on the receiving end of a software engineering interview. But I still remember my favorite interview question. It was at MemSQL circa 2013.
This blog post discusses a programming challenge from a software engineering interview. memcached, an in-memory key-value store, provides a built-in way to atomically add k to a number, but it doesn’t provide other arithmetic operations – there is no ‘atomic multiply by k’ operation. The challenge required interviewees to add a `mult` command to memcached. The challenge is well calibrated for interviews as there is only one correct answer and it is also a good representation of what most real-world programming is like.
Go, Python, Rust, and production AI applications – Sameer Ajmani
In this article, I’ll talk about Go, Python, and Rust, and each language’s role in building AI-powered applications. Python was the first programming language I ever loved, and Go was the sec…
Source: Go, Python, Rust, and production AI applications – Sameer Ajmani
Interview at KZSB “Money Talk” on AI
KZSB radio interview from Monday May 15, 2023, on AI/ML, and especially ChatGPT. Link to Apple Podcast.
KVTA 1590 interview on Cloud and AI
May 8, 2023, with Tom Spence, on KVTA 1590
The podcast of the entire KVTA Morning Show with Spence can be found here and my presentation starts 3hrs and 38min into the show (3:38).
Computer Science 11th Advisory Board Meeting
The 11th Computer Science Advisory Board meeting at California State University Channel Islands will take place on May 5, 2023, 12:00-2:00pm, in Sierra Hall 1411, followed by the Capstone Showcase in the Sierra Hall lobby, 2:00-4:00pm.


Agenda
- Lunch while meeting
- Chris Meissner: Welcome by Chris Meissner
a. Introductions of board members - Michael Soltys: Departmental update 10 min
a. Enrollment challenges
b. Scott Feister: HPC competition
c. Kevin Scrivnor: Krypto competition
e. EDC/GBL/AWS Upskilling opportunity - Member profile: Alan Jaeger on Fathomwerx at Port Hueneme 30 min
- Update on new programs
a. Eric Kaltman: Gaming
b. Reza Abdolee: Cybersecurity
c. Vida Vakilian: SCADA Essential and Data Management - Jason Isaacs: update on Mechatronics ABET accreditation
- Open discussion with board members
{kind=link}
most Important: CaPstone Showcase
- Aaron Forman: http://aaronformancapstone.cikeys.com/uncategorized/capstone/
- Hayley Ruttenberg: http://hayleyruttenberg.cikeys.com/capstone/
- Ramtin Saremi: https://www.iprogress-app-ramtin-saremi.cikeys.com
- Elias Serzhan: http://eliasserzhancapstone.cikeys.com/capstone-project/
- Ian Khoo, Escaping Inferno, http://khoocapstone.cikeys.com/
- Stephen Snebold, Hostile Entities, http://hostileentitesdelvolperbbog.cikeys.com/
- Ashley Gray https://ashleygray-projects.cikeys.com/capstone/
- Alexis Gomez http://agomezcapstone.cikeys.com/
- Aaron Urrea https://blog.aaronurrea.com
- BABS Team: http://babs.cikeys.com/
- Acoustic Gripper Team: http://crsm.cikeys.com
- Solar Team: http://projectascension.cikeys.com/blog/
- GARLIC Team: http://kchebrard75.cikeys.com/
- Enrique Garcia and Eli Clemens: https://castmap.cikeys.com/
- Charlie Hernandez & Zachary Drake: http://hw04db.cikeys.com/blog/
- Andrew Graves: andrewcgraves.com/capstone
- Jamie Hernandez: https://jamiehernandez.cikeys.com/
- https://vhp.vbnfiredefense.com/
- Jacob Gelman: https://j94021.cikeys.com
- Mario Ayala Fuentes: http://webprogrammingit380.cikeys.com/security-risk-assessment-app/
- Tyler Mclaughlin and Rica Ley Madayag: https://cinetworkingautomation.wordpress.com
- Sheradyn Ruef: http://capstone-sheradynruef.cikeys.com/capstone/mvts
- Adam Larson: https://adamlarson535.cikeys.com/capstone/
- Frances Zercher: https://csuciwarriors.wordpress.com/2023/05/04/project-page-csuci-warriors/
- Amanda Dawley: https://amandadawley499.cikeys.com/
- Taseen Hafiz: http://taseenhafiz.cikeys.com/capstone/uncategorized/human-robot-interaction-with-hand-gestures/
- Jaskirat Singh: https://jascapstone2023spring.cikeys.com/video-game-classification-system/
- Jon Roeske, Evan Miller and Huey Hsu: http://jonroeske.cikeys.com/
- Shani Melbourne and Denise Anciola: https://capstone.deniseanciola.cikeys.com/Capstone/19-2/
- Rebecca Freeman: http://chefsquest.cikeys.com/project-page/
- Alexandra Credico: https://snortidps.wordpress.com
- Kadejha Jones: https://www.kadejhajones.com/my-educational-journey/capstone-project
- Eddie Lovato: https://edwardlovatoiii315.cikeys.com/home/
- Madayln Henderson: http://chs100databaseproject.cikeys.com/blog/quienes-son-ellos/
- Nancy Ambriz Madelyne Lu: https://madelynelu.cikeys.com/capstone/
More pictures























Computer Science 10th Advisory Board Meeting
The 10th Computer Science Advisory Board (AB) meeting at California State University Channel Islands will take place on December 2, 2022, 12:00-2:00pm, in the Evans room at the Broome Library (Broome 2533), followed by the Capstone Showcase in the Sierra Hall lobby, 2:00-4:00pm.

Agenda
- Welcome by Chris Meissner, Chair of the Computer Science Advisory Board
- Introductions
- Update on the Department, by Michael Soltys, Chair of the Department of Computer Science:
- Thank you to Susan and Bob Brown for donating for our students to go to coding competitions
- Dr. Larry Masinter donated to the CS Department and SHFT to support student research collaboration with Interlisp.org, a 501c(3) devoted to the preservation of the ACM award-winning Medley / Interlisp System developed at Xerox PARC
- Also donations from Allan Gottlieb, American Endowment Foundation, Kevin Knoedler, Randall McNary and Meissner Filtration.
- 3 of us are tenured, and 2 more have gone up for tenure this year.
- We are struggling with enrollment
- Updates from faculty:
- Reza Abdolee and Vida Vakilian: Establishment of new lab in Ojai with Industrial Control System testbeds; Reza will update on Cybersecurity efforts; also on a new partnership with Rockwell Automation
- Scott Feister: Dept of Energy and SuperComputing competition
- Eric Kaltman: Established online presence for the Software History Futures and Technologies (SHFT) research group: https://www.shft.group ; signed a publication contract for a short book, An Overview of Emulation as a Preservation Method, for the Council of Library and Information Resources (CLIR) “Pocket Burgundy” Series; Established a computer game lab at CI with staffed student support for 30 hours a week; Game Development Minor Revision is nearing complete approval for 2023-2024
- Jason Isaacs: ABET for Mechatronics; see slides below.
- Brian Thoms: “Formation and Action of a Learning Community with Collaborative Learning Software,” accepted into the Journal of Management Information Systems
- Bahareh Abbasi: Purchasing an industrial robotic arm for Robotics lab, Sawyer robot from Rethink Robotics
- Discussion
- 2:00pm walk over to Sierra Hall for Capstone Showcase
Expo-Presentation-1
most Important: CaPstone Showcase
- Luis Chavez – https://cluis492.cikeys.com/capstone/polycrystalline-capstone-webpage/
- Eli Flores – http://nft.eliflores947.cikeys.com/nft/
- http://jerinsharif.cikeys.com/jerin-sharif-capstone-fall-2022/
- Norah Milne – Nonogram Me – http://picrossme.cikeys.com/nonogramme-final/
- Desireé Caldera and Evan Jacobs – Entertainment Technology Center Data Analysis – http://desireecaldera-capstone.cikeys.com/uncategorized/etc-technology-center-data-analysis/
- Evan Burschinger – Project Rogue Mind – http://evan.cikeys.com/project-rogue-mind/
- Jeffrey Foyil – Academon – https://academon407191796.wordpress.com/
- Christopher Chang – QCSimple – http://qcsimple-dev.cikeys.com/project-presentation/
- Brandon Marziole – http://bmarziole.cikeys.com/
- Adam Hesse – http://capstonepresentation.adamhesse.cikeys.com/blog/
- http://tbmlocationmarketinganalysis.cikeys.com/
- https://barkle-app.com/
- https://spotter.rivera.cikeys.com/
- http://plctrafficlight.cikeys.com/
- Daniel Rojas: https://capstone-drb.cikeys.com
- Tyler Sellers: https://tylersellers.cikeys.com
- PatrickMcdonough: http://corrosion.cikeys.com/capstone/uncategorized/computational-aspects-of-peridynamic-corrosion-damage-modeling-and-svet-verification-techniques/
- Daren Brown: http://darenbrown.cikeys.com/Capstone/it499/it499/
- https://safewater.cikeys.com/
- https://hvpn.danberbs.cikeys.com/
- http://davidreillycapstone499-09.cikeys.com/
- Dominique Malgeri: http://demalgeri.cikeys.com/28-2/
- http://capstone.seaneigle.cikeys.com/
- http://katsotto.capstone.comp380assign.cikeys.com/
- http://nvargas.cikeys.com/
- https://ajtolley.cikeys.com/Capstone/
Mule Days in Bishop, CA






Computer Science 9th Advisory Board Meeting

The 9th Computer Science Advisory Board (AB) meeting at California State University Channel Islands took place on May 13, 2022, 1:00-2:00pm, followed by the Capstone Showcase in the Sierra Hall lobby.
The chair of the AB is Chris Meissner (photo left), who introduced the meeting. As there were construction closures on campus, some AB members did not make it to the meeting, but were able to attend the Capstone showcase which followed immediately 2:00-3:00.
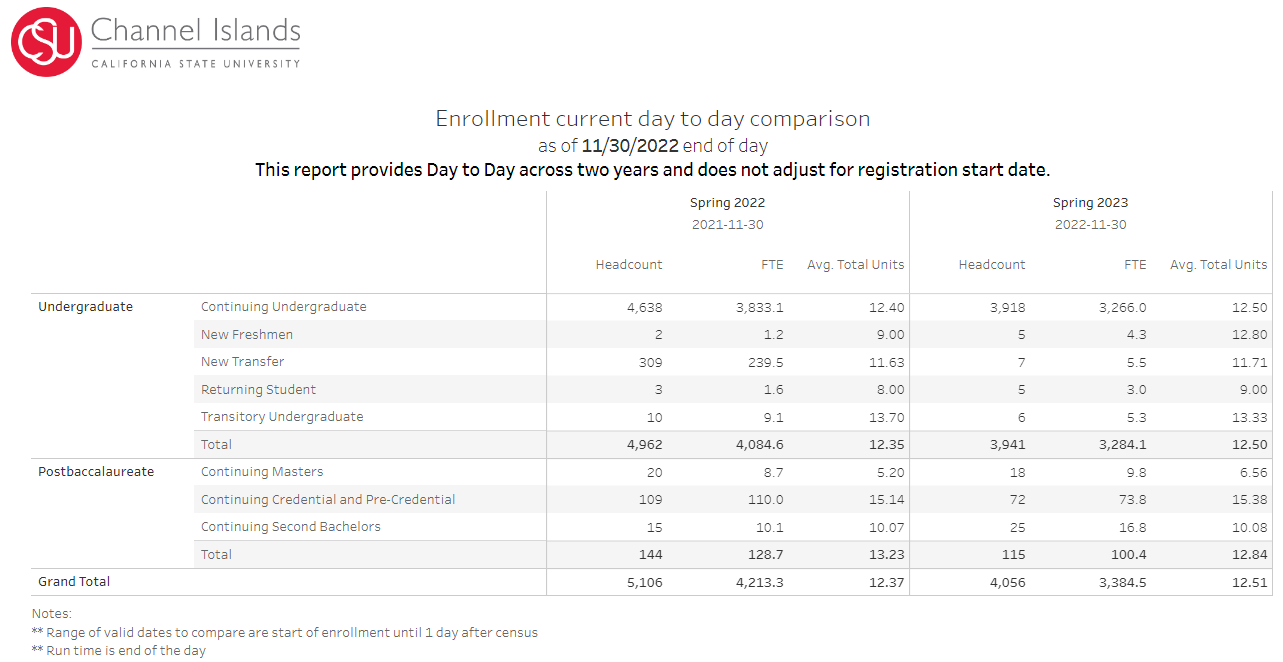
Michael Soltys, the chair of the department of Computer Science, gave a short update on the department including the enrollment numbers:
| Computer Science | Information Technology | Mechatronics Engineering | |
| Fall 2021 | 264 | 77 | 67 |
| Spring 2022 | 279 | 83 | 63 |
Professor Jason Isaacs is going to be sending an email to the AB to review the Program Educational Outcomes (PEOs), which is one or the roles of the AB for ABET accreditation. The last time the PEOs were examined was at the 3rd AB meeting in November 2018.
Eric Kaltman discussed his work on revamping the Minor in Gaming, a popular minor with students; and a great way of attracting students to the Computer Science department. The slides of the presentation are given at the end of this page.
Timur Taluy from FileYourTaxes gave a presentation on his company, its recent fast growth, and mentioned how CI students were hired over the years, both as interns and permanent employees, and about the deployment of AWS cloud technology (which we teach at CI) to meet the sudden spikes in demand (especially around tax day every year) without making permanent capital investments in hardware infrastructure.
most Important: CaPstone Showcase
- http://wetravel.cikeys.com
- https://alexflux.com/capstone
- https://csurene.cikeys.com/capstone
- https://www.wavezsurfapp.com/
- https://jlloyd-it380.cikeys.com/
- https://roquegarciacapstonemobileapp.cikeys.com/
- https://mechatronicforklift.cikeys.com/
- http://projectbounder.cikeys.com/
- http://plcfactorymodel.cikeys.com/
- https://franciscofunescapstone.cikeys.com/
- http://travisclarkddd.cikeys.com
- http://skyhampton744.cikeys.com/
- www.cbombs.com
- http://earonbihis139.cikeys.com/
- http://victormaldonado.cikeys.com/author/admin/
- https://pk3capstonecomp499.cikeys.com/dual-modality-human-recognition-a-csuci-computer-science-capstone-project/
- roquegarciacapstonemobileapp.cikeys.com
- https://edgarramirez136.cikeys.com/blog/
- http://maxwelllight238.cikeys.com/
- http://malakaicapstone.cikeys.com/uncategorized/poster-demo-video/
- https://tannerhugli.wixsite.com/my-site
- http://kiddiebot.cikeys.com/
- https://hadland.cikeys.com/project-page/
- http://ilanharari.cikeys.com/uncategorized/entertainment-data-visualization/
- https://alexandracampbell559.cikeys.com/Capstone2022blog/uncategorized/capstone-2022-section-004/
- ttps://elizabethgerbasi.cikeys.com/evacuation-center-database-system/
- http://charityislands.cikeys.com/
Slides on games minor
Slides of Prof Eric Kaltman on the revamped Games Minor.
CSUCI_Business_Advisor_Meeting_2022