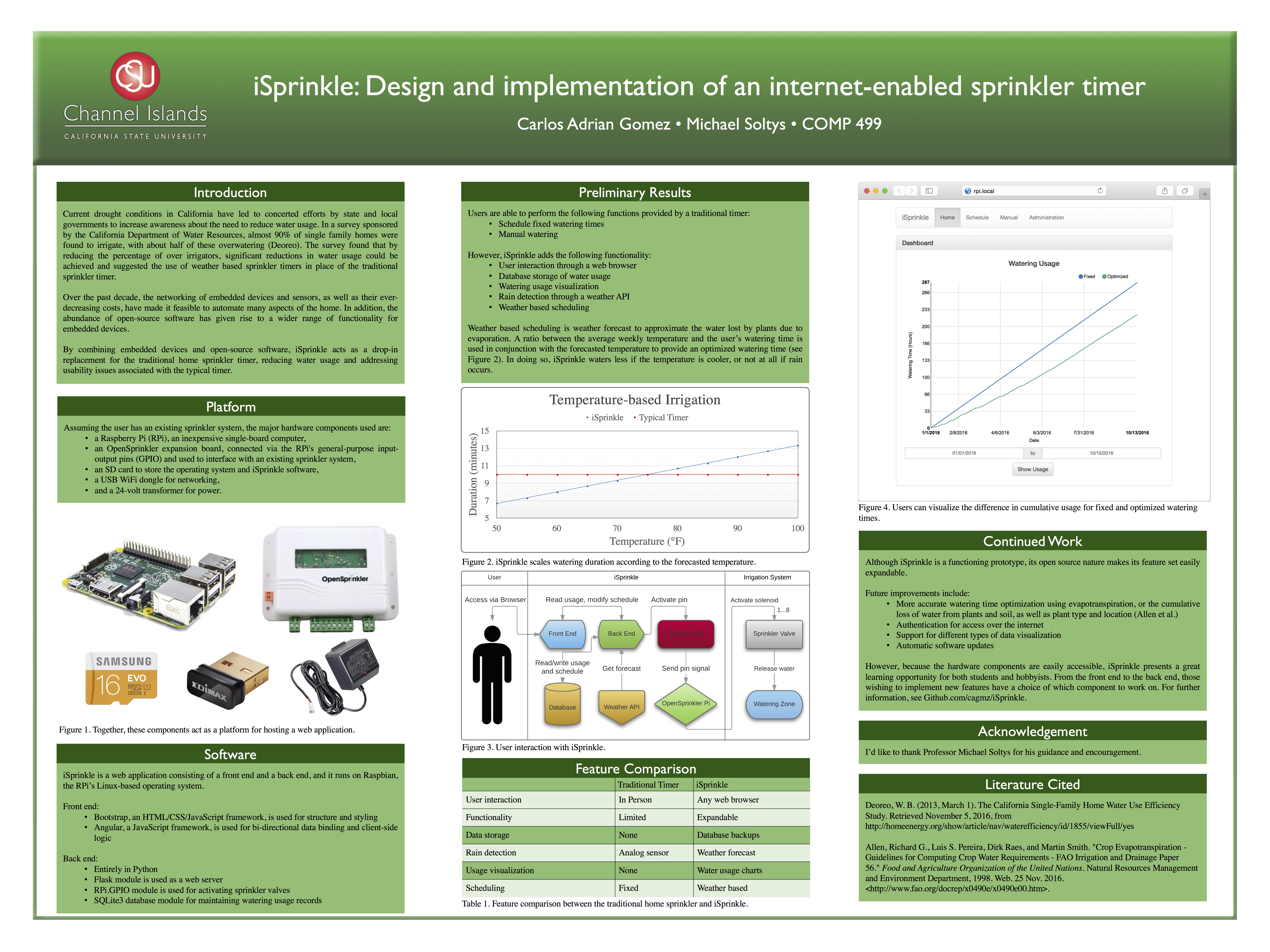
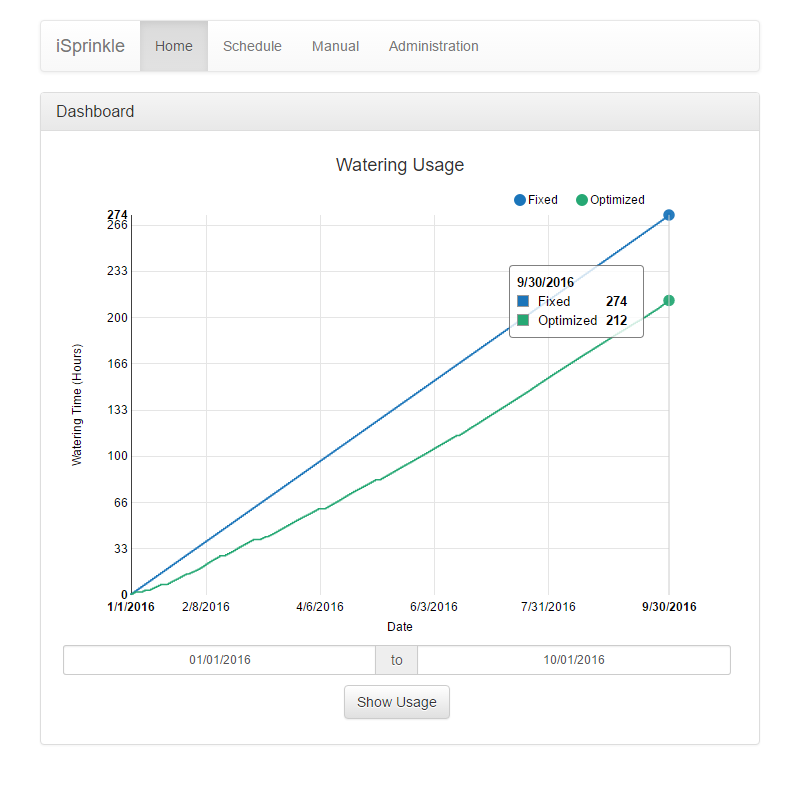
iSprinkle is a Raspberry Pi powered irrigation controller which will allow a user to set an initial irrigation schedule for a sprinkler system using a web interface, after which it will use the local weather forecast to adjust the base watering schedule as needed. iSprinkle is the result of a senior Capstone project (COMP499) at California State University Channel Islands, undertaken by student Carlos Gomez in 2016, advised by Michael Soltys. A detailed write up of the project, where we partnered with Prof. Adam Sędziwy (who visited CI in June 2016), can be found here:
iSprinkle is a Raspberry Pi powered irrigation controller which will allow a user to set an initial irrigation schedule for a sprinkler system using a web interface, after which it will use the local weather forecast to adjust the base watering schedule as needed. iSprinkle is the result of a senior Capstone project (COMP499) at California State University Channel Islands, undertaken by student Carlos Gomez in 2016, advised by Michael Soltys. A detailed write up of the project, where we partnered with Prof. Adam Sędziwy (who visited CI in June 2016), can be found here:
A short version of the above paper will be presented at INDOTEC2017:
iSprinkle was also presented at SCCUR 2016, the Southern California Council for Undergraduate Research Conference at UC Riverside on November 12, 2016.
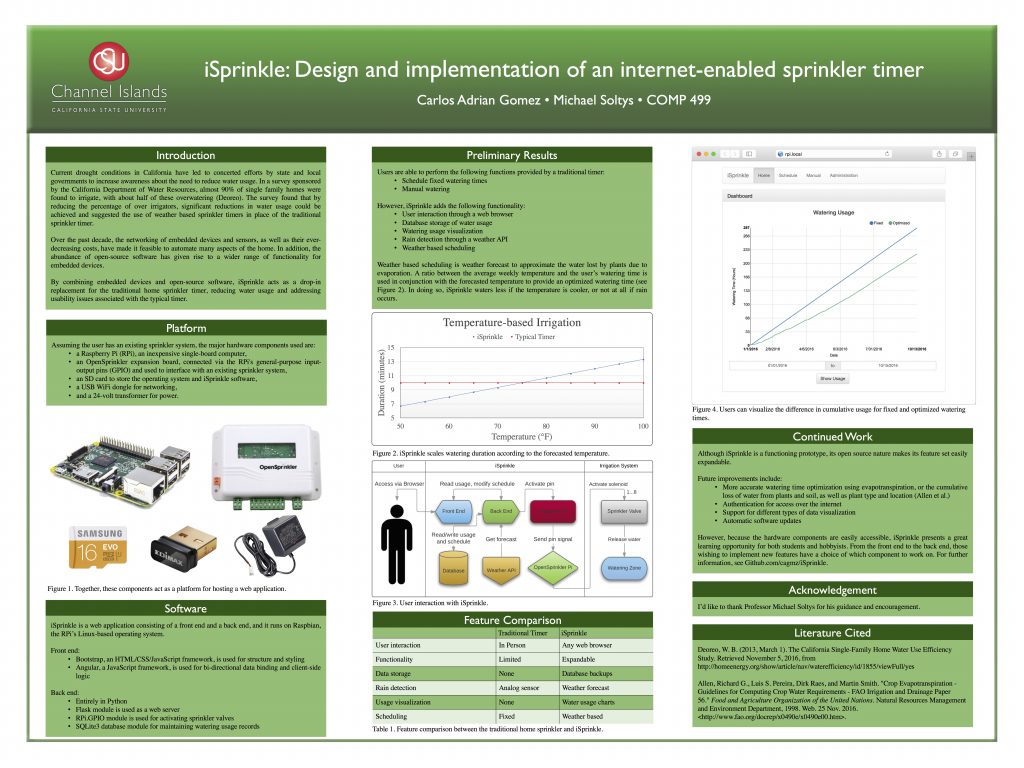
The design of a system such as iSprinkle requires a holistic approach that is very different from most class assignments. The former usually span a few files that are to be turned in within a week or two, making it difficult to implement a system with many “moving parts.” However, iSprinkle’s functionality is divided between the front-end and back-end, both of which need to communicate so that the user’s requests are fulfilled. Designing such a system requires taking into consideration many aspects; from major decisions such as deciding on a backend language to use, to minutiae such as the date and time formats to use across the backend and front end to maintain consistency.
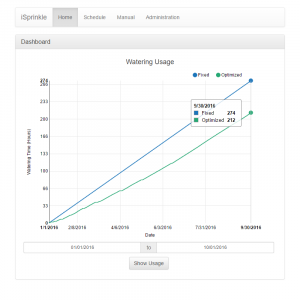 By doing so, iSprinkle will be able to irrigate more efficiently compared to a fixed schedule; by progrmmatically modifying the user’s watering schedule, iSprinkle will increase/decrease the amount of watering that the schedule dictates depending on data that it receives from a weather API. iSprinkle hopes to make it easier for homeowners to conserve water by automating adjustments to their irrigation schedule.
By doing so, iSprinkle will be able to irrigate more efficiently compared to a fixed schedule; by progrmmatically modifying the user’s watering schedule, iSprinkle will increase/decrease the amount of watering that the schedule dictates depending on data that it receives from a weather API. iSprinkle hopes to make it easier for homeowners to conserve water by automating adjustments to their irrigation schedule.
 Carlos Adrian Gomez has since graduated from CI, and is working as a Software Engineer in the Ventura area.
Carlos Adrian Gomez has since graduated from CI, and is working as a Software Engineer in the Ventura area.
Carlos’ on twitter